The trust boundary
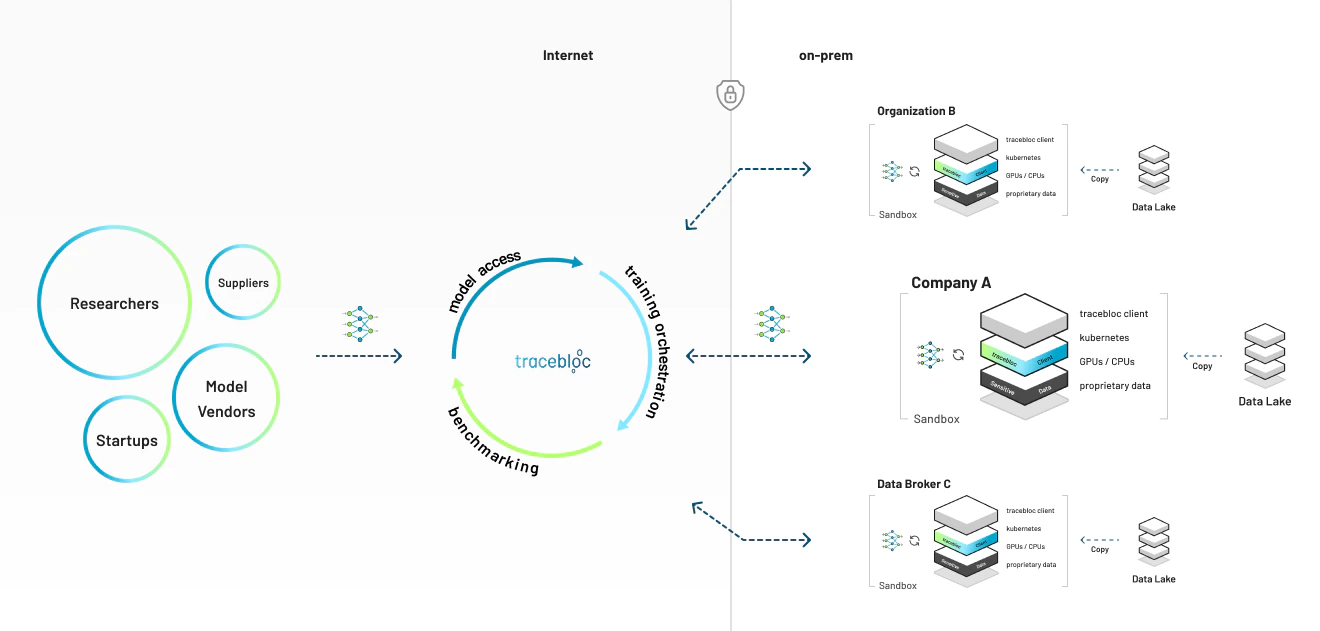
How it works
1
Deploy your workspace
One command sets up your private workspace on your own infrastructure — a laptop, an on-prem server, or a cloud cluster.
2
Ingest your datasets
Stage your training and test data locally. Metadata syncs to the platform so contributors can see what’s available — the raw data never moves.
3
Create a use case
Define a use case from your datasets and set how submitted models are evaluated.
4
Invite contributors
Whitelist contributors by email. Only the people you invite can take part.
5
Contributors submit and train models
Each model is scanned for vulnerabilities, then trains against your data in an isolated container, on your hardware.
6
Only results are shared
Training and evaluation results flow back to you over TLS. Trained model weights are shared only if you choose to — you control that in the admin panel.
What stays, what leaves
Enforced by per-job container isolation, a NetworkPolicy that blocks data egress from training pods, a vulnerability scan before any model runs, and TLS on all traffic.
The mental model:
1 machine = 1 workspace = n datasets. One deployment per machine; as many datasets inside it as you like.Vocabulary
What it touches
The installer changes only Docker and~/.tracebloc on your host — no system-wide changes. Uninstalling is a single command, and your data is yours throughout.
Get started
Quick Start
A running workspace in about 10 minutes, with one command.
Deployment environments
Deploy on local / k3d, bare-metal, EKS, AKS, or OpenShift.
Want the guarantees in detail for your security team? See Security & data handling.