> ## Documentation Index
> Fetch the complete documentation index at: https://docs.tracebloc.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Start Training
> Step-by-step guide to training a model on the tracebloc platform.
You have joined a use case and accepted the terms. Training a model is easy: you run a Jupyter notebook locally to connect and submit models to the workspace.
For a smooth first run, let's follow the step by step notebook in the public [GitHub repository](https://github.com/tracebloc/start-training/tree/main) along with the documentation below.
Alternatively, you may use the notebook hosted in [Google Colab](https://colab.research.google.com/drive/1N00idtpoaq1lk9OJE6g4bMqd8o-Qex2C#scrollTo=uuHJeLTP338z) and jump directly to [Step 1](#1-connect-to-the-tracebloc-workspace).
## Pull Training Notebook and Model Repositories
On your machine, create a tracebloc folder and pull the [Training GitHub repository](https://github.com/tracebloc/start-training/tree/main) and the [Model Zoo GitHub repository](https://github.com/tracebloc/model-zoo/tree/master). The notebook contains all commands to connect and start training, the model zoo contains a selection of compatible models ready for training. The easiest way to customize models is by starting from the model zoo. Open a terminal and run the following commands:
```bash theme={null}
mkdir tracebloc && cd tracebloc
git clone https://github.com/tracebloc/start-training.git
git clone https://github.com/tracebloc/model-zoo.git
cd start-training
```
Then, install the [Anaconda](https://www.anaconda.com/docs/getting-started/anaconda/install) package manager.
## Create a Virtual Environment
Create a new environment, name it for example "tracebloc":
```bash theme={null}
conda create -n tracebloc python=3.9
conda activate tracebloc
```
Then, install requirements:
```bash theme={null}
python -m pip install --upgrade pip
# Install with the extra that matches your framework:
pip install "tracebloc[pytorch]>=0.8.1"
# pip install "tracebloc[tensorflow]>=0.8.1"
# pip install "tracebloc[sklearn]>=0.8.1"
# pip install "tracebloc[all]>=0.8.1" # legacy behaviour — all frameworks
```
## Install and Launch Jupyter Notebook
Install Jupyter into your environments:
```bash theme={null}
conda install jupyter notebook
```
Launch the notebook:
```bash theme={null}
jupyter notebook notebooks/traceblocTrainingGuide.ipynb
```
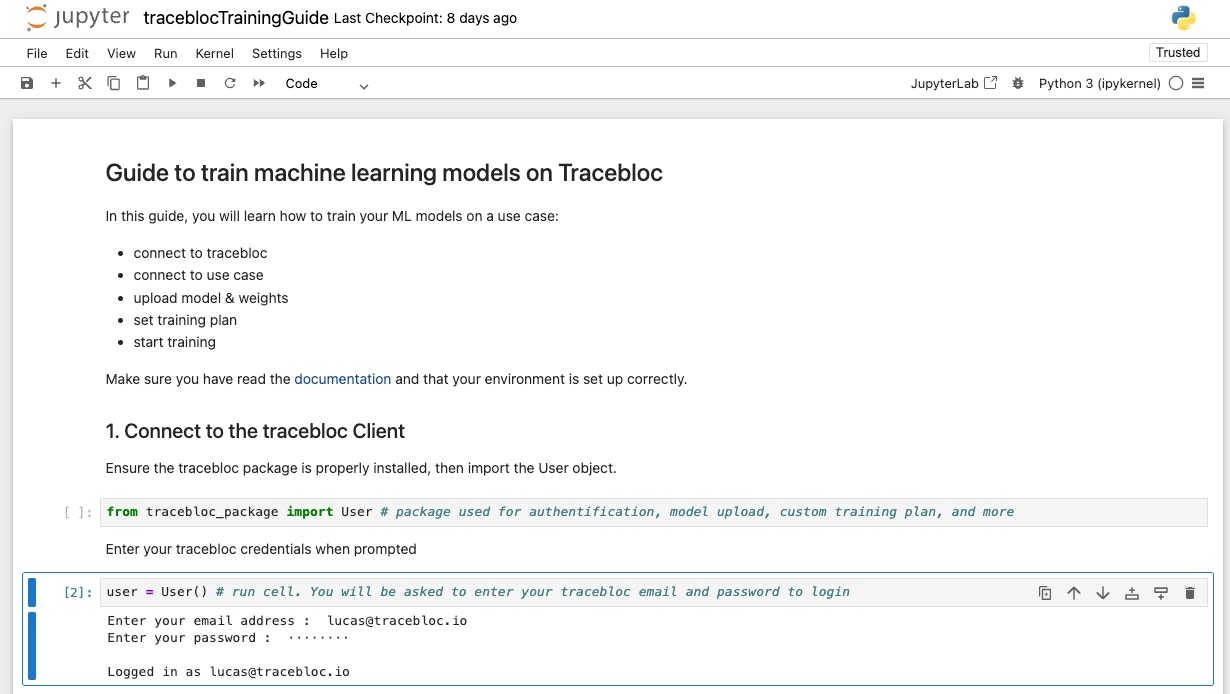
## 1. Connect to the tracebloc workspace
Follow the instructions in the notebook to authenticate. Have your tracebloc user credentials ready:
 ### Getting Help
For more info about available functions and methods, call the help function:
```python theme={null}
user.help()
```
## 2. Upload Model & Customize
Choose a model from the [tracebloc model zoo](https://github.com/tracebloc/model-zoo), it is the easiest way to get started. The model zoo provides starter templates you can modify freely. Make sure the mandatory variables in your model file match the use case parameters. You can find all the necessary info from the use case description and exploratory data analysis (EDA).
Alternatively, you can define your own architecture from scratch.
### Model Parameters by Task
| Data Type | Task | Model Parameters |
| --------- | ---------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| Image | Classification | `image_size` has to match image x/y-dimensions
### Getting Help
For more info about available functions and methods, call the help function:
```python theme={null}
user.help()
```
## 2. Upload Model & Customize
Choose a model from the [tracebloc model zoo](https://github.com/tracebloc/model-zoo), it is the easiest way to get started. The model zoo provides starter templates you can modify freely. Make sure the mandatory variables in your model file match the use case parameters. You can find all the necessary info from the use case description and exploratory data analysis (EDA).
Alternatively, you can define your own architecture from scratch.
### Model Parameters by Task
| Data Type | Task | Model Parameters |
| --------- | ---------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| Image | Classification | `image_size` has to match image x/y-dimensions
`output_classes` has to match # of image classes |
| Image | Object Detection | `image_size` has to match image x/y-dimensions
`output_classes` has to match # of object types |
| Image | Semantic Segmentation | `image_size` has to match image x/y-dimensions
`output_classes` has to match # of object classes |
| Image | Keypoint Detection | `image_size` has to match image x/y-dimensions
`output_classes` has to match # of object classes
`num_feature_points` has to match # of keypoints |
| Tabular | Tabular Classification | `output_classes` has to match # of classes
`num_feature_points` has to match # of features |
| Text | Text Classification | `input_shape`
`sequence_length`
`output_classes` |
### Example
A 3-way classification task on 224x224 images with LeNet would need the following lenet.py configuration:
```python theme={null}
import torch
import torch.nn as nn
# Mandatory variables, adapt as necessary.
framework = "pytorch"
main_class = "MyModel"
image_size = 224
batch_size = 16
output_classes = 3
category = "image_classification"
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(3, 6, kernel_size=5, stride=1, padding=0),
nn.BatchNorm2d(6),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.layer2 = nn.Sequential(
nn.Conv2d(6, 16, kernel_size=5, stride=1, padding=0),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.fc = nn.Linear(16 * 53 * 53, 120)
self.relu = nn.ReLU()
self.fc1 = nn.Linear(120, 84)
self.relu1 = nn.ReLU()
self.fc2 = nn.Linear(84, output_classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
out = self.relu(out)
out = self.fc1(out)
out = self.relu1(out)
out = self.fc2(out)
return out
```
The **variables at the top are mandatory** for the use case workspace but the model definition is fully flexible. Open the model file from the model zoo in your editor, e.g.:
```
model-zoo/model_zoo/image_classification/pytorch/lenet.py
```
Modify the architecture however you like: add layers, change activations, swap to a different backbone entirely. The only requirement is that the mandatory variables (`framework`, `main_class`, `image_size`, `batch_size`, `output_classes`, `category`) stay consistent with the use case parameters.
In case of multiple uploads, only the most recently uploaded model will be linked to the dataset.
### Upload
Upload the model to the use case workspace from your notebook:
```python theme={null}
user.upload_model(model_name="../../model-zoo/model_zoo///model.py")
```
For details on model code formats, mandatory variables per framework, and pre-trained weights, see [Customize Models](/join-use-case/model-optimization).
## 3. Link Model with Dataset
Navigate to the use case and copy the "Training Dataset ID" at the center of the use case pane and enter it to establish the link
```python theme={null}
training_plan = user.link_model_dataset(dataset_id='Dataset ID')
```
You should get "Assignment successful!" and the dataset parameters.
## 4. Set Training Plan
Set the experiment name and configure hyperparameters.
```python theme={null}
# Set experiment name
training_plan.experiment_name("My Experiment")
# Set training parameters
training_plan.epochs(10)
...
# Get training plan
training_plan.get_training_plan()
```
Get the training plan to check settings before you start the training. For a detailed list of all hyperparameter options, see [Hyperparameters](/join-use-case/hyperparameters).
For classical, non federated and non gradient descent-based machine learning algorithms like random forests, XGBoost, SVMs, logistic regression, use simplified settings:
```python theme={null}
# Set training parameters
training_plan.epochs(1)
# Set federated learning cycles = 1
training_plan.cycles(1)
```
## 5. Start Training
To send the model to the workspace infrastructure and start training on the training data, run:
```python theme={null}
training_plan.start()
```
Go to the [tracebloc website](https://ai.tracebloc.io/my-use-cases) and your use case, then navigate to the "Training/Finetuning" tab you will see your experiment. Monitor the training process hover over the learning curves to check the performance at specific epochs and cycles.
If you want to run a second experiment, overwrite parameters and re-start training with `training_plan.start()`.
### Pause, Re-Start and Stop:
To pause, stop, or resume running experiments, click here:
 Once stopped, an experiment cannot be rerun.
**Note:** The compute budget is set by the use case owner. Your team shares one compute budget with no per-person limit.
## Submit an Experiment to the Leaderboard
Once training is complete, submit your best model to the leaderboard for evaluation on the test dataset. For the full submission flow and leaderboard details, see the [Evaluate Model guide](/join-use-case/model-evaluation#submit-to-leaderboard).
## Inviting Others to Your Team
See the [Join guide](/join-use-case/join-use-case#inviting-others-to-your-team) for instructions.
## Next Steps
* customize models: Follow [model optimisation](/join-use-case/model-optimization).
***
## Need Help?
For more info about available functions and methods, call the help function in your notebook:
```python theme={null}
user.help()
```
* Email us at [support@tracebloc.io](mailto:support@tracebloc.io)
Once stopped, an experiment cannot be rerun.
**Note:** The compute budget is set by the use case owner. Your team shares one compute budget with no per-person limit.
## Submit an Experiment to the Leaderboard
Once training is complete, submit your best model to the leaderboard for evaluation on the test dataset. For the full submission flow and leaderboard details, see the [Evaluate Model guide](/join-use-case/model-evaluation#submit-to-leaderboard).
## Inviting Others to Your Team
See the [Join guide](/join-use-case/join-use-case#inviting-others-to-your-team) for instructions.
## Next Steps
* customize models: Follow [model optimisation](/join-use-case/model-optimization).
***
## Need Help?
For more info about available functions and methods, call the help function in your notebook:
```python theme={null}
user.help()
```
* Email us at [support@tracebloc.io](mailto:support@tracebloc.io)